Der sort-Befehl wird verwendet, um Textdateien oder die Ausgabe von Befehlen zu sortieren. Er ordnet die Zeilen in einer bestimmten Reihenfolge anhand deren Inhalt. Man kann mit sort Daten in aufsteigender oder absteigender Reihenfolge sortieren oder spezifische Sortierkriterien anwenden.
Syntax
sort [OPTION] [DATEI]...Einige häufig verwendete Optionen sind:
-roder--reverse: Sortiert die Zeilen in umgekehrter Reihenfolge.-noder--numeric-sort: Sortiert numerische Werte anstelle von alphanumerischen Werten.-foder--ignore-case: Sortiert die Zeilen, ohne auf die Groß- und Kleinschreibung zu achten.-k Noder--key=N: Sortiert die Zeilen basierend auf einem bestimmten Feld (Spalte)Nin der Datei.-uoder--unique: Entfernt doppelte Zeilen und gibt nur eindeutige Zeilen aus.
Beispiele
Für die folgenden Beispiele generieren wir eine Datei mit dem Namen unsortierte_datei_mit_dopplungen.txt und folgendem Inhalt:
Linux
Linux
Ubuntu
Fedora
Debian
Debian
Fedora
Fedora
Ubuntu
Debian
Arch
LinuxSortieren einer Datei in aufsteigender Reihenfolge
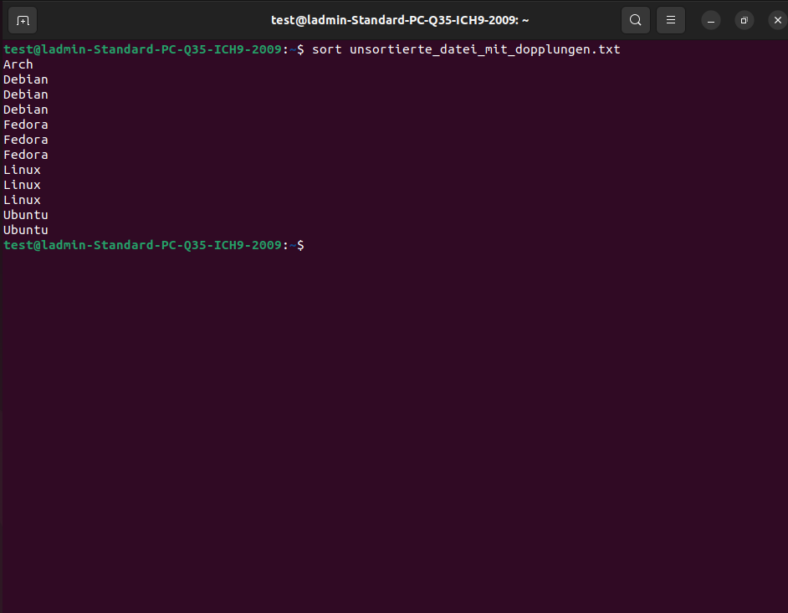
Um diese Datei in aufsteigender Reihenfolge zu sortieren, verwenden wir den Befehl:
$ sort unsortierte_datei_mit_dopplungen.txt
Arch
Debian
Debian
Debian
Fedora
Fedora
Fedora
Linux
Linux
Linux
Ubuntu
Ubuntu
$ Sortieren einer Datei in absteigender Reihenfolge
Um die Datei in absteigender Reihenfolge zu sortieren, verwenden wir die Option -r:
$ sort -r unsortierte_datei_mit_dopplungen.txt
Ubuntu
Ubuntu
Linux
Linux
Linux
Fedora
Fedora
Fedora
Debian
Debian
Debian
Arch
$ Sortieren einer Datei numerisch
Angenommen, wir haben eine Datei unsortierte_zahlen_mit_dopplungen.txt mit numerischen Werten:
3
6
6
15
2
9
9
6
623
2Um diese Datei zu sortieren, verwenden wir die Option -n:
$ sort -n unsortierte_zahlen_mit_dopplungen.txt
2
2
3
6
6
6
9
9
15
623
$ Entfernen von Duplikaten in sortierten Daten
Der sort-Befehl kann in Kombination mit dem uniq-Befehl verwendet werden, um Duplikate zu entfernen. Zuerst sortieren wir die Datei und verwenden dann uniq einmal als Befehl, den wir die Ausgabe von sort geben und einmal mit der Option -u:
$ sort unsortierte_datei_mit_dopplungen.txt | uniq
Arch
Debian
Fedora
Linux
Ubuntu
$ sort -u unsortierte_datei_mit_dopplungen.txt
Arch
Debian
Fedora
Linux
Ubuntu
$ Links
- https://wiki.ubuntuusers.de/sort/: Eine Seite im Ubuntuusers Wiki, die Informationen zum
sort-Befehl in Ubuntu bietet, einschließlich Anwendungsbeispielen. - https://www.linux-community.de/ausgaben/linuxuser/2005/01/zu-befehl-sort/: Ein Artikel aus dem LinuxUser-Magazin, der eine Einführung und Beispiele zur Verwendung des
sort-Befehls gibt. - https://man7.org/linux/man-pages/man1/sort.1.html: Die offizielle Manpage (Handbuchseite) des
sort-Befehls in Linux mit ausführlicher Dokumentation und Syntax. - https://www.geeksforgeeks.org/sort-command-linuxunix-examples/: Ein Artikel auf GeeksforGeeks, der verschiedene Beispiele und Anwendungen des
sort-Befehls in Linux/Unix behandelt.