Der uniq-Befehl ist äußerst nützlich, wenn es darum geht, doppelte Zeilen aus Textdateien oder Ausgaben zu entfernen. Er arbeitet aufeinanderfolgende Zeilen ab und gibt nur eine Instanz jeder eindeutigen Zeile aus.
Syntax
uniq [Optionen] [Eingabe] [Ausgabe]Einige Beispiele für häufig verwendete Optionen sind:
-coder--count: Zählt die Anzahl der Vorkommen jeder Zeile und fügt sie vor jeder Zeile ein.-doder--repeated: Zeigt nur Zeilen an, die sich wiederholen.-ioder--ignore-case: Ignoriert die Groß-/Kleinschreibung bei der Überprüfung auf Duplikate.-uoder--unique: Zeigt nur eindeutige Zeilen an (ohne Duplikate).-f Noder--skip-fields=N: Ignoriert die erstenNFelder einer Zeile beim Vergleich auf Duplikate.
Beispiele
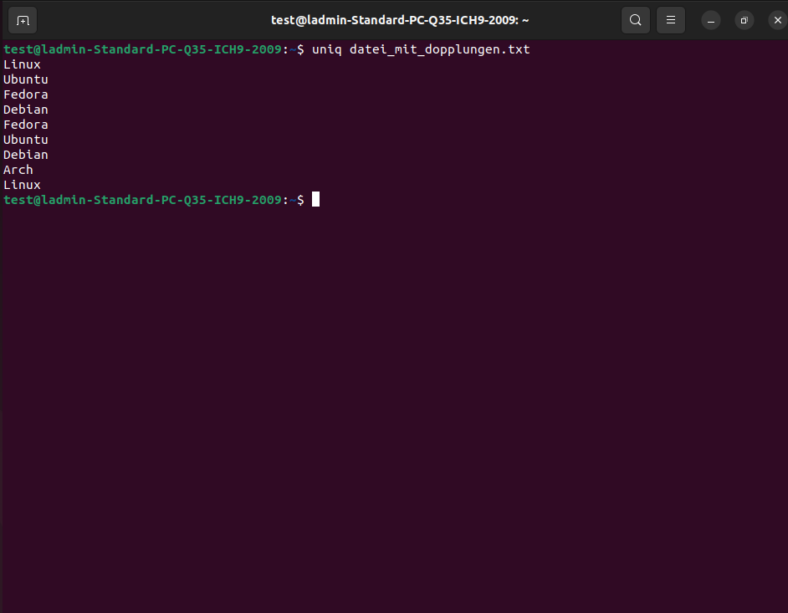
Für die folgenden Beispiele generieren wir eine Datei mit dem Namen datei_mit_dopplungen.txt und folgendem Inhalt:
Linux
Linux
Ubuntu
Fedora
Fedora
Fedora
UbuntuEntfernen von doppelten Zeilen in einer Datei
Wir können den uniq-Befehl verwenden, um die doppelten Zeilen zu entfernen, allerdings müssen die Dopplungen aufeinander folgen:
$ uniq datei_mit_dopplungen.txt
Linux
Ubuntu
Fedora
Ubuntu
$ Anzeigen der Anzahl der Vorkommen jeder Zeile
Wenn wir die Anzahl der Vorkommen jeder Zeile anzeigen möchten, können wir die Option -c verwenden:
$ uniq -c datei_mit_dopplungen.txt
2 Linux
1 Ubuntu
3 Fedora
1 Ubuntu
$ Verwendung von uniq mit sort zur Entfernung von Duplikaten in sortierten Daten
Der uniq-Befehl wird oft in Verbindung mit dem Befehl sort verwenden, um die Datei vor der Verwendung von uniq zu sortieren:
$ sort datei_mit_dopplungen.txt | uniq
Fedora
Linux
Ubuntu
$ Links
- https://linuxhint.com/linux_uniq_command/: LinuxHint bietet einen Artikel, der den
uniq-Befehl in Linux erklärt und Beispiele für dessen Verwendung liefert. - https://wiki.ubuntuusers.de/uniq/: Das Ubuntuusers-Wiki enthält eine Seite, die Informationen über den
uniq-Befehl in Ubuntu bereitstellt. - https://geek-university.com/uniq-befehl/: Geek University hat eine detaillierte Erklärung des
uniq-Befehls in Linux. Der Artikel enthält grundlegende Informationen, Optionen und praktische Beispiele. - https://man7.org/linux/man-pages/man1/uniq.1.html: Die offizielle Linux Manpage für den
uniq-Befehl bietet eine umfassende Dokumentation und eine detaillierte Beschreibung der Optionen und der Verwendung des Befehls. - https://www.geeksforgeeks.org/uniq-command-in-linux-with-examples/: GeeksforGeeks hat einen Artikel, der den
uniq-Befehl in Linux erläutert und verschiedene Beispiele für seine Anwendung zeigt. Der Artikel ist hilfreich, um das Konzept und die Verwendung vonuniqbesser zu verstehen.